Apache Spark
#Data Engineering
- 2 minutes read - 289 words
large scale data processing distributed compute engine.
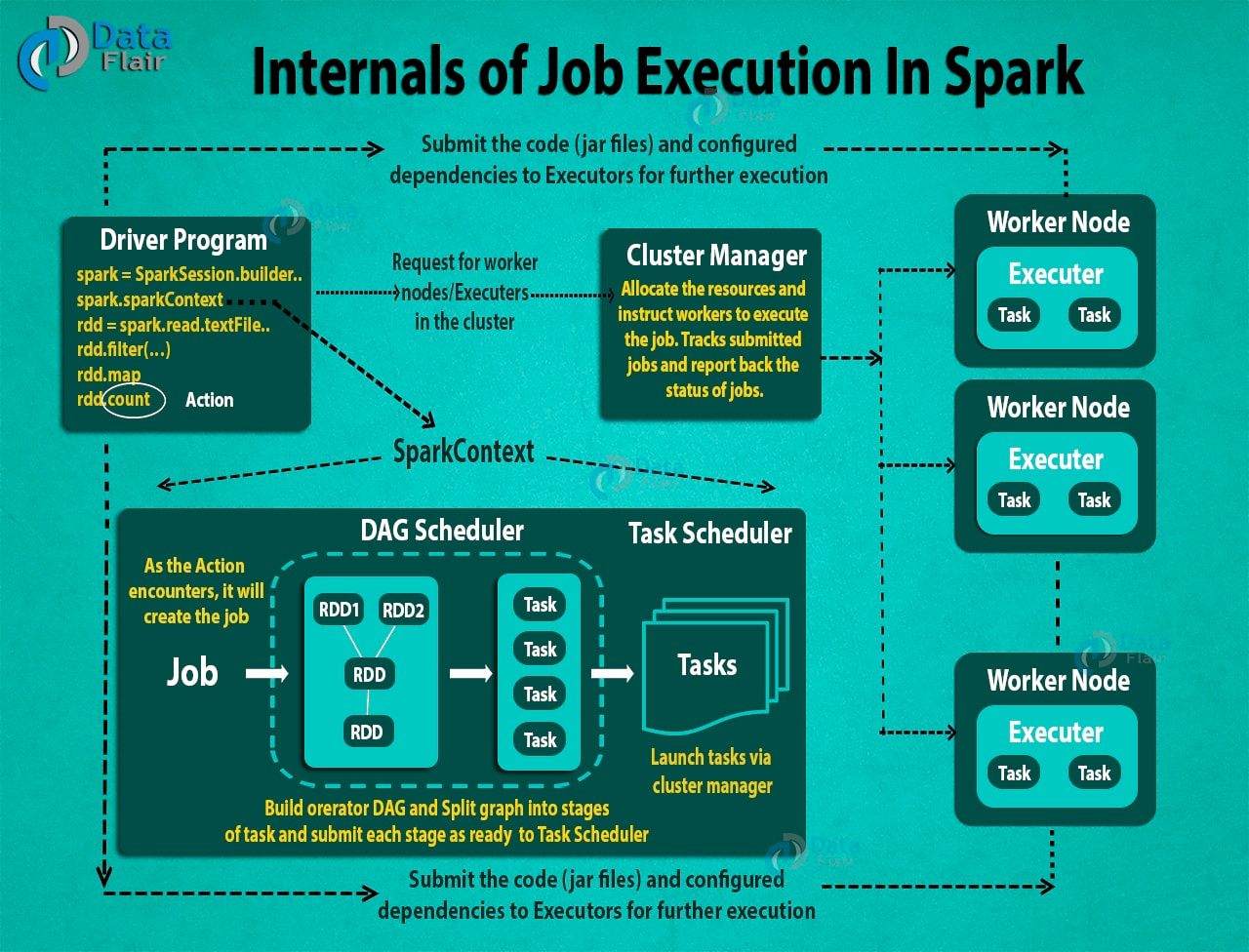
Master slave architecture: central coordinator is called Driver and Slaves are called Executors. Spark Cluster Manager is default but Yarn and Mesos can be used as well.
RDD: Resilient Distributed Dataset
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph(DAG) and so able to recompute missing or damaged partitions due to node failures.
- Distributed, since Data resides on multiple nodes.
- Dataset represents records of the data you work with. The user can load the data set externally which can be either JSON file, CSV file, text file or database via JDBC with no specific data structure
Immutablity : data cannot be changed only transformed from one form to another
Fault-tolerant: a lineage graphs helps to restore data to it’s previous form in case of a failure.
Lazy Evaluation : computation happens when the result is needed, else all operations just create a lineage DAG
RDD are supposed to be stored in RAM to make processing faster but it can be stored on disk at cost of expensive IO same as HDFS
SparkContext
client of spark execution environment (driver and executors).
- Getting the current status of spark application
- Canceling the job
- Canceling the Stage
- Running job synchronously
- Running job asynchronously
- Accessing persistent RDD
- Unpersisting RDD
- Programmable dynamic allocation
Spark Application: self-contained computation that runs user code
Task, Job and Stage : Job is set of parallel computation divided into multiple Tasks where tasks are single unit of instruction for an executor, job are divided into statges
main() function of the user supplied code runs in Driver process which creates SparkContext, RDD and generated Tasks for executor after implicitly creating the DAG of execution plan, it then schduled the task over available executors.